# 分库分表
# 基本介绍
- 什么是分库分表
当我们使用读写分离、索引、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了。
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
- 为什么要使用分库分表
分库分表可以提升系统的稳定性跟负载能力,不存在单库/单表大数据。没有高并发的性能瓶颈,增加系统可用性。缺点是分库表无法join,只能通过接口方式解决,提高了系统复杂度。
- shardingsphere 数据库中间件
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。
他们均提供标准化的数据分片、读写分离、多数据副本、数据加密、影子库压测、分布式事务和数据库治理等功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-JDBC最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为ShardingSphere,
2020年4月16日正式成为Apache软件基金会的顶级项目,同时兼容多种数据库,通过可插拔架构,理想情况下,可以做到对业务代码无感知。
shardingsphere 特点
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL
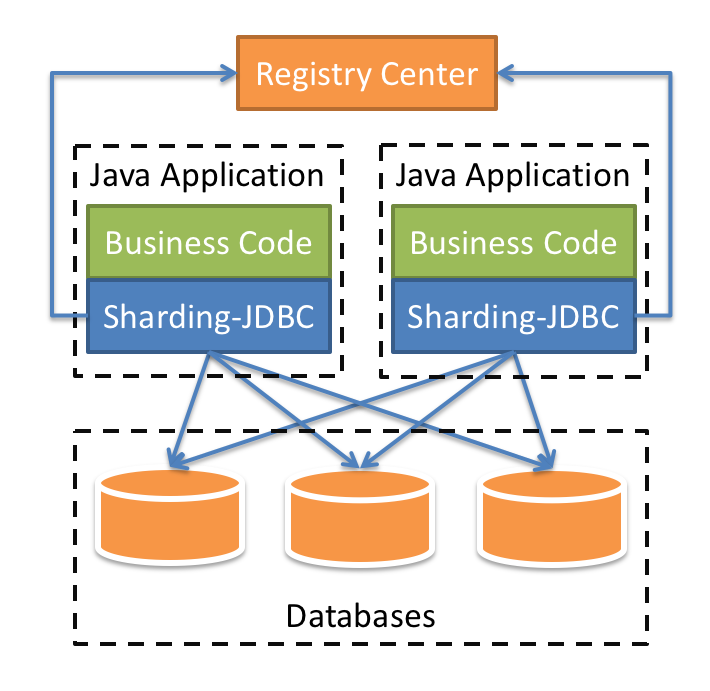
下面是shardingsphere的架构图:

# 使用手册
本部分是介绍Sharding-JDBC相关使用。
# 数据分配
引入Maven依赖
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
基于Java编码的规则配置
Sharding-JDBC的分库分表通过规则配置描述,以下例子是根据user_id取模分库, 且根据order_id取模分表的两库两表的配置。
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第一个数据源
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://localhost:3306/ds0");
dataSource1.setUsername("root");
dataSource1.setPassword("");
dataSourceMap.put("ds0", dataSource1);
// 配置第二个数据源
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://localhost:3306/ds1");
dataSource2.setUsername("root");
dataSource2.setPassword("");
dataSourceMap.put("ds1", dataSource2);
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable("t_order");
orderTableRuleConfig.setActualDataNodes("ds${0..1}.t_order${0..1}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 省略配置order_item表规则...
// ...
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), new Properties());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
基于Yaml的规则配置
dataSources:
ds0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0
username: root
password:
ds1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1
username: root
password:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmInlineExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmInlineExpression: t_order${order_id % 2}
t_order_item:
actualDataNodes: ds${0..1}.t_order_item${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmInlineExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmInlineExpression: t_order_item${order_id % 2}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 读写分离
引入Maven依赖
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
基于Java编码的规则配置
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置主库
BasicDataSource masterDataSource = new BasicDataSource();
masterDataSource.setDriverClassName("com.mysql.jdbc.Driver");
masterDataSource.setUrl("jdbc:mysql://localhost:3306/ds_master");
masterDataSource.setUsername("root");
masterDataSource.setPassword("");
dataSourceMap.put("ds_master", masterDataSource);
// 配置第一个从库
BasicDataSource slaveDataSource1 = new BasicDataSource();
slaveDataSource1.setDriverClassName("com.mysql.jdbc.Driver");
slaveDataSource1.setUrl("jdbc:mysql://localhost:3306/ds_slave0");
slaveDataSource1.setUsername("root");
slaveDataSource1.setPassword("");
dataSourceMap.put("ds_slave0", slaveDataSource1);
// 配置第二个从库
BasicDataSource slaveDataSource2 = new BasicDataSource();
slaveDataSource2.setDriverClassName("com.mysql.jdbc.Driver");
slaveDataSource2.setUrl("jdbc:mysql://localhost:3306/ds_slave1");
slaveDataSource2.setUsername("root");
slaveDataSource2.setPassword("");
dataSourceMap.put("ds_slave1", slaveDataSource2);
// 配置读写分离规则
MasterSlaveRuleConfiguration masterSlaveRuleConfig = new MasterSlaveRuleConfiguration("ds_master_slave", "ds_master", Arrays.asList("ds_slave0", "ds_slave1"));
// 获取数据源对象
DataSource dataSource = MasterSlaveDataSourceFactory.createDataSource(createDataSourceMap(), masterSlaveRuleConfig, new HashMap<String, Object>(), new Properties());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
基于Yaml的规则配置
dataSources:
ds_master: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_master
username: root
password:
ds_slave0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_slave0
username: root
password:
ds_slave1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_slave1
username: root
password:
masterSlaveRule:
name: ds_ms
masterDataSourceName: ds_master
slaveDataSourceNames: [ds_slave0, ds_slave1]
props:
sql.show: true
configMap:
key1: value1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 强制路由
ShardingSphere使用ThreadLocal管理分片键值进行Hint强制路由。可以通过编程的方式向HintManager中添加分片条件,该分片条件仅在当前线程内生效。
1.分片字段不存在SQL中、数据库表结构中,而存在于外部业务逻辑。因此,通过Hint实现外部指定分片结果进行数据操作。
2.强制在主库进行某些数据操作。
配置
使用hint进行强制数据分片,需要使用HintManager搭配分片策略配置共同使用。若DatabaseShardingStrategy配置了Hint分片算法,则可使用HintManager进行分库路由结果的注入。同理,若TableShardingStrategy配置了Hint分片算法,则同样可 使用HintManager进行分表路由结果的注入。所以使用Hint之前,需要配置Hint分片算法。
参考配置如下:
shardingRule:
tables:
t_order:
actualDataNodes: demo_ds_${0..1}.t_order_${0..1}
databaseStrategy:
hint:
algorithmClassName: io.shardingsphere.userAlgo.HintAlgorithm
tableStrategy:
hint:
algorithmClassName: io.shardingsphere.userAlgo.HintAlgorithm
defaultTableStrategy:
none:
defaultKeyGeneratorClassName: io.shardingsphere.core.keygen.DefaultKeyGenerator
props:
sql.show: true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
实例化
HintManager hintManager = HintManager.getInstance();
添加分片键值
- 使用hintManager.addDatabaseShardingValue来添加数据源分片键值。
- 使用hintManager.addTableShardingValue来添加表分片键值。
分库不分表情况下,强制路由至某一个分库时,可使用hintManager.setDatabaseShardingValue方式添加分片。通过此方式添加分片键值后,将跳过SQL解析和改写阶段,从而提高整体执行效率。
清除分片键值
分片键值保存在ThreadLocal中,所以需要在操作结束时调用hintManager.close()来清除ThreadLocal中的内容。
hintManager实现了AutoCloseable接口,可推荐使用try with resource自动关闭。
// Sharding database and table with using hintManager.
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.addDatabaseShardingValue("t_order", 1);
hintManager.addTableShardingValue("t_order", 2);
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
// Sharding database without sharding table and routing to only one database with using hintManger.
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
基于暗示(Hint)的强制主库路由
实例化
- 与基于暗示(Hint)的数据分片相同。
设置主库路由
- 使用hintManager.setMasterRouteOnly设置主库路由。
清除分片键值
- 与基于暗示(Hint)的数据分片相同。
完整代码示例
String sql = "SELECT * FROM t_order";
try (
HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.setMasterRouteOnly();
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# 数据治理
使用数据治理功能需要指定一个注册中心。配置将全部存入注册中心,可以在每次启动时使用本地配置覆盖注册中心配置,也可以只通过注册中心读取配置。
引入Maven依赖
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-orchestration-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!--若使用zookeeper, 请加入下面Maven坐标-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-orchestration-reg-zookeeper-curator</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!--若使用etcd, 请加入下面Maven坐标-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-orchestration-reg-etcd</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
基于Java编码的规则配置
// 省略配置dataSourceMap以及shardingRuleConfig
// ...
// 配置注册中心
RegistryCenterConfiguration regConfig = new RegistryCenterConfiguration();
regConfig.setServerLists("localhost:2181");
regConfig.setNamespace("sharding-sphere-orchestration");
// 配置数据治理
OrchestrationConfiguration orchConfig = new OrchestrationConfiguration("orchestration-sharding-data-source", regConfig, false);
// 获取数据源对象
DataSource dataSource = OrchestrationShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), new Properties(), orchConfig);
2
3
4
5
6
7
8
9
10
11
12
13
基于Yaml的规则配置
orchestration:
name: orchestration-sharding-data-source
overwrite: false
registry:
serverLists: localhost:2181
namespace: sharding-sphere-orchestration
2
3
4
5
6
# 分布式事务
引入Maven依赖
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-spring</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
<version>${spring-boot.version}</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
连接池配置
ShardingSphere支持将普通的数据库连接池,转换为支持XA事务的连接池,对HikariCP, Druid和DBCP2连接池内置支持,无需额外配置。 其它连接池需要用户实现DataSourceMapConverter的SPI接口进行扩展,可以参考io.shardingsphere.transaction.xa.convert.swap.HikariParameterSwapper的实现。 若ShardingSphere无法找到合适的实现,则会按默认的配置创建XA事务连接池。默认属性如下:
| 属性名称 | 默认值 |
|---|---|
| connectionTimeoutMilliseconds | 30 * 1000 |
| idleTimeoutMilliseconds | 60 * 1000 |
| maintenanceIntervalMilliseconds | 30 * 1000 |
| maxLifetimeMilliseconds | 0 (无限制) |
| maxPoolSize | 50 |
| minPoolSize | 1 |
事务类型切换
ShardingSphere的事务类型存放在TransactionTypeHolder的本地线程变量中,因此在数据库连接创建前修改此值,可以达到自由切换事务类型的效果。
注意
数据库连接创建之后,事务类型将无法更改。
API方式
TransactionTypeHolder.set(TransactionType.LOCAL);
或
TransactionTypeHolder.set(TransactionType.XA);
AutoConfiguration配置
@SpringBootApplication(exclude = JtaAutoConfiguration.class)
@ComponentScan("io.shardingsphere.transaction.aspect")
public class StartMain {
}
2
3
4
业务代码
在需要事务的方法或类中添加相关注解即可,例如:
@ShardingTransactionType(TransactionType.LOCAL)
@Transactional
2
或
@ShardingTransactionType(TransactionType.XA)
@Transactional
2
注意
@ShardingTransactionType需要同Spring的@Transactional配套使用,事务才会生效。
Atomikos参数配置
ShardingSphere默认的XA事务管理器为Atomikos。 可以通过在项目的classpath中添加jta.properties来定制化Atomikos配置项。 具体的配置规则请参考Atomikos (opens new window)的官方文档。
# 配置手册
本部分是Sharding-JDBC的配置参考手册,需要时可当做字典查阅。
# Java配置
数据分片
DataSource getShardingDataSource() throws SQLException
{
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
shardingRuleConfig.getBroadcastTables().add("t_config");
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(
new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("order_id", new ModuloShardingTableAlgorithm()));
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig);
}
TableRuleConfiguration getOrderTableRuleConfiguration()
{
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("t_order");
result.setActualDataNodes("ds${0..1}.t_order${0..1}");
result.setKeyGeneratorColumnName("order_id");
return result;
}
TableRuleConfiguration getOrderItemTableRuleConfiguration()
{
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("t_order_item");
result.setActualDataNodes("ds${0..1}.t_order_item${0..1}");
return result;
}
Map<String, DataSource> createDataSourceMap()
{
Map<String, DataSource> result = new HashMap<>();
result.put("ds0", DataSourceUtil.createDataSource("ds0"));
result.put("ds1", DataSourceUtil.createDataSource("ds1"));
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
读写分离
DataSource getMasterSlaveDataSource() throws SQLException
{
MasterSlaveRuleConfiguration masterSlaveRuleConfig = new MasterSlaveRuleConfiguration();
masterSlaveRuleConfig.setName("ds_master_slave");
masterSlaveRuleConfig.setMasterDataSourceName("ds_master");
masterSlaveRuleConfig.setSlaveDataSourceNames(Arrays.asList("ds_slave0", "ds_slave1"));
return MasterSlaveDataSourceFactory.createDataSource(createDataSourceMap(), masterSlaveRuleConfig,
new LinkedHashMap<String, Object>(), new Properties());
}
Map<String, DataSource> createDataSourceMap()
{
Map<String, DataSource> result = new HashMap<>();
result.put("ds_master", DataSourceUtil.createDataSource("ds_master"));
result.put("ds_slave0", DataSourceUtil.createDataSource("ds_slave0"));
result.put("ds_slave1", DataSourceUtil.createDataSource("ds_slave1"));
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
数据分片 + 读写分离
DataSource getDataSource() throws SQLException
{
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
shardingRuleConfig.getBroadcastTables().add("t_config");
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(
new StandardShardingStrategyConfiguration("user_id", new ModuloShardingDatabaseAlgorithm()));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("order_id", new ModuloShardingTableAlgorithm()));
shardingRuleConfig.setMasterSlaveRuleConfigs(getMasterSlaveRuleConfigurations());
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig,
new HashMap<String, Object>(), new Properties());
}
TableRuleConfiguration getOrderTableRuleConfiguration()
{
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("t_order");
result.setActualDataNodes("ds_${0..1}.t_order_${[0, 1]}");
result.setKeyGeneratorColumnName("order_id");
return result;
}
TableRuleConfiguration getOrderItemTableRuleConfiguration()
{
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("t_order_item");
result.setActualDataNodes("ds_${0..1}.t_order_item_${[0, 1]}");
return result;
}
List<MasterSlaveRuleConfiguration> getMasterSlaveRuleConfigurations()
{
MasterSlaveRuleConfiguration masterSlaveRuleConfig1 = new MasterSlaveRuleConfiguration("ds_0",
"demo_ds_master_0", Arrays.asList("demo_ds_master_0_slave_0", "demo_ds_master_0_slave_1"));
MasterSlaveRuleConfiguration masterSlaveRuleConfig2 = new MasterSlaveRuleConfiguration("ds_1",
"demo_ds_master_1", Arrays.asList("demo_ds_master_1_slave_0", "demo_ds_master_1_slave_1"));
return Lists.newArrayList(masterSlaveRuleConfig1, masterSlaveRuleConfig2);
}
Map<String, DataSource> createDataSourceMap()
{
final Map<String, DataSource> result = new HashMap<>();
result.put("demo_ds_master_0", DataSourceUtil.createDataSource("demo_ds_master_0"));
result.put("demo_ds_master_0_slave_0", DataSourceUtil.createDataSource("demo_ds_master_0_slave_0"));
result.put("demo_ds_master_0_slave_1", DataSourceUtil.createDataSource("demo_ds_master_0_slave_1"));
result.put("demo_ds_master_1", DataSourceUtil.createDataSource("demo_ds_master_1"));
result.put("demo_ds_master_1_slave_0", DataSourceUtil.createDataSource("demo_ds_master_1_slave_0"));
result.put("demo_ds_master_1_slave_1", DataSourceUtil.createDataSource("demo_ds_master_1_slave_1"));
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
数据治理
DataSource getDataSource() throws SQLException
{
return OrchestrationShardingDataSourceFactory.createDataSource(createDataSourceMap(),
createShardingRuleConfig(), new HashMap<String, Object>(), new Properties(),
new OrchestrationConfiguration("orchestration-sharding-data-source", getRegistryCenterConfiguration(),
false));
}
private RegistryCenterConfiguration getRegistryCenterConfiguration()
{
RegistryCenterConfiguration regConfig = new RegistryCenterConfiguration();
regConfig.setServerLists("localhost:2181");
regConfig.setNamespace("sharding-sphere-orchestration");
return regConfig;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
配置项说明
数据分片
ShardingDataSourceFactory 数据分片的数据源创建工厂。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| dataSourceMap | Map<String, DataSource> | 数据源配置 |
| shardingRuleConfig | ShardingRuleConfiguration | 数据分片配置规则 |
| configMap | Map<String, Object> | 用户自定义配置 |
| props | Properties | 属性配置 |
ShardingRuleConfiguration 分片规则配置对象。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| tableRuleConfigs | Collection<TableRuleConfiguration> | 分片规则列表 |
| bindingTableGroups | Collection<String> | 绑定表规则列表 |
| broadcastTables | Collection<String> | 广播表规则列表 |
| defaultDataSourceName | String | 未配置分片规则的表将通过默认数据源定位 |
| defaultDatabaseShardingStrategyConfig | ShardingStrategyConfiguration | 默认分库策略 |
| defaultTableShardingStrategyConfig | ShardingStrategyConfiguration | 默认分表策略 |
| defaultKeyGenerator | KeyGenerator | 默认自增列值生成器,缺省使用DefaultKeyGenerator |
| masterSlaveRuleConfigs | Collection<MasterSlaveRuleConfiguration> | 读写分离规则,缺省表示不使用读写分离 |
TableRuleConfiguration 表分片规则配置对象。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| logicTable | String | 逻辑表名称 |
| actualDataNodes | String | 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点。用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况 |
| databaseShardingStrategyConfig | ShardingStrategyConfiguration | 分库策略,缺省表示使用默认分库策略 |
| tableShardingStrategyConfig | ShardingStrategyConfiguration | 分表策略,缺省表示使用默认分表策略 |
| logicIndex | String | 逻辑索引名称,对于分表的Oracle/PostgreSQL数据库中DROP INDEX XXX语句,需要通过配置逻辑索引名称定位所执行SQL的真实分表 |
| keyGeneratorColumnName | String | 自增列名称,缺省表示不使用自增主键生成器 |
| keyGenerator | KeyGenerator | 自增列值生成器,缺省表示使用默认自增主键生成器 |
StandardShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于单分片键的标准分片场景。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingColumn | String | 分片列名称 |
| preciseShardingAlgorithm | PreciseShardingAlgorithm | 精确分片算法,用于=和IN |
| rangeShardingAlgorithm | RangeShardingAlgorithm | 范围分片算法,用于BETWEEN |
ComplexShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于多分片键的复合分片场景。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingColumns | String | 分片列名称,多个列以逗号分隔 |
| shardingAlgorithm | ComplexKeysShardingAlgorithm | 复合分片算法 |
InlineShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于配置行表达式分片策略。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingColumn | String | 分片列名称 |
| algorithmExpression | String | 分片算法行表达式,需符合groovy语法,详情请参考 行表达式 (opens new window) |
HintShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于配置Hint方式分片策略。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| shardingAlgorithm | HintShardingAlgorithm | Hint分片算法 |
NoneShardingStrategyConfiguration
ShardingStrategyConfiguration的实现类,用于配置不分片的策略。
PropertiesConstant
属性配置项,可以为以下属性。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| sql.show | boolean | 是否开启SQL显示,默认值: false |
| executor.size | int | 工作线程数量,默认值: CPU核数 |
| max.connections.size.per.query | int | 每个物理数据库为每次查询分配的最大连接数量。默认值: 1 |
| check.table.metadata.enabled | boolean | 是否在启动时检查分表元数据一致性,默认值: false |
configMap
用户自定义配置。
读写分离
MasterSlaveDataSourceFactory 读写分离的数据源创建工厂。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| dataSourceMap | Map<String, DataSource> | 数据源与其名称的映射 |
| masterSlaveRuleConfig | MasterSlaveRuleConfiguration | 读写分离规则 |
| configMap | Map<String, Object> | 用户自定义配置 |
| props | Properties | 属性配置 |
MasterSlaveRuleConfiguration 读写分离规则配置对象。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| name | String | 读写分离数据源名称 |
| masterDataSourceName | String | 主库数据源名称 |
| slaveDataSourceNames | Collection<String> | 从库数据源名称列表 |
| loadBalanceAlgorithm | MasterSlaveLoadBalanceAlgorithm | 从库负载均衡算法 |
configMap
用户自定义配置。
PropertiesConstant
属性配置项,可以为以下属性。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| sql.show | boolean | 是否开启SQL显示,默认值: false |
| executor.size | int | 用于SQL执行的工作线程数量,为零则表示无限制。默认值: 0 |
| max.connections.size.per.query | int | 每个物理数据库为每次查询分配的最大连接数量。默认值: 1 |
| check.table.metadata.enabled | boolean | 是否在启动时检查分表元数据一致性,默认值: false |
数据治理
OrchestrationShardingDataSourceFactory
数据分片 + 数据治理的数据源工厂。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| dataSourceMap | Map<String, DataSource> | 同ShardingDataSourceFactory |
| shardingRuleConfig | ShardingRuleConfiguration | 同ShardingDataSourceFactory |
| configMap | Map<String, Object> | 同ShardingDataSourceFactory |
| props | Properties | 同ShardingDataSourceFactory |
| orchestrationConfig | OrchestrationConfiguration | 数据治理规则配置 |
OrchestrationMasterSlaveDataSourceFactory
读写分离 + 数据治理的数据源工厂。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| dataSourceMap | Map<String, DataSource> | 同MasterSlaveDataSourceFactory |
| masterSlaveRuleConfig | MasterSlaveRuleConfiguration | 同MasterSlaveDataSourceFactory |
| configMap | Map<String, Object> | 同MasterSlaveDataSourceFactory |
| props | Properties | 同MasterSlaveDataSourceFactory |
| orchestrationConfig | OrchestrationConfiguration | 数据治理规则配置 |
OrchestrationConfiguration
数据治理规则配置对象。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| name | String | 数据治理实例名称 |
| overwrite | boolean | 本地配置是否覆盖注册中心配置,如果可覆盖,每次启动都以本地配置为准 |
| regCenterConfig | RegistryCenterConfiguration | 注册中心配置 |
RegistryCenterConfiguration
用于配置注册中心。
| 名称 | 数据类型 | 说明 |
|---|---|---|
| serverLists | String | 连接注册中心服务器的列表。包括IP地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181 |
| namespace | String | 注册中心的命名空间 |
| digest | String | 连接注册中心的权限令牌。缺省为不需要权限验证 |
| operationTimeoutMilliseconds | int | 操作超时的毫秒数,默认500毫秒 |
| maxRetries | int | 连接失败后的最大重试次数,默认3次 |
| retryIntervalMilliseconds | int | 重试间隔毫秒数,默认500毫秒 |
| timeToLiveSeconds | int | 临时节点存活秒数,默认60秒 |
# Yaml配置
数据分片
dataSources:
ds0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0
username: root
password:
ds1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1
username: root
password:
shardingRule:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order${order_id % 2}
keyGeneratorColumnName: order_id
t_order_item:
actualDataNodes: ds${0..1}.t_order_item${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item${order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds0
defaultTableStrategy:
none:
defaultKeyGeneratorClassName: io.shardingsphere.core.keygen.DefaultKeyGenerator
props:
sql.show: true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
读写分离
dataSources:
ds_master: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_master
username: root
password:
ds_slave0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_slave0
username: root
password:
ds_slave1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_slave1
username: root
password:
masterSlaveRule:
name: ds_ms
masterDataSourceName: ds_master
slaveDataSourceNames:
- ds_slave0
- ds_slave1
props:
sql.show: true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
数据分片 + 读写分离
dataSources:
ds0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0
username: root
password:
ds0_slave0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0_slave0
username: root
password:
ds0_slave1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0_slave1
username: root
password:
ds1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1
username: root
password:
ds1_slave0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1_slave0
username: root
password:
ds1_slave1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1_slave1
username: root
password:
shardingRule:
tables:
t_order:
actualDataNodes: ms_ds${0..1}.t_order${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ms_ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order${order_id % 2}
keyGeneratorColumnName: order_id
t_order_item:
actualDataNodes: ms_ds${0..1}.t_order_item${0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ms_ds${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item${order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds_0
defaultTableStrategy:
none:
defaultKeyGeneratorClassName: io.shardingsphere.core.keygen.DefaultKeyGenerator
masterSlaveRules:
ms_ds0:
masterDataSourceName: ds0
slaveDataSourceNames:
- ds0_slave0
- ds0_slave1
loadBalanceAlgorithmType: ROUND_ROBIN
configMap:
master-slave-key0: master-slave-value0
ms_ds1:
masterDataSourceName: ds1
slaveDataSourceNames:
- ds1_slave0
- ds1_slave1
loadBalanceAlgorithmType: ROUND_ROBIN
configMap:
master-slave-key1: master-slave-value1
props:
sql.show: true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
数据治理
#省略数据分片和读写分离配置
orchestration:
name: orchestration_ds
overwrite: true
registry:
namespace: orchestration
serverLists: localhost:2181
2
3
4
5
6
7
8
配置项说明 config-xxx.yaml 数据分片+读写分离(根据3.1最新版本修订)
# 以下配置截止版本为3.1
# 配置文件中,必须配置的项目为schemaName,dataSources,并且sharidngRule,masterSlaveRule,配置其中一个(注意,除非server.yaml中定义了Orchestration,否则必须至少有一个config-xxxx配置文件),除此之外的其他项目为可选项
schemaName: test # schema名称,每个文件都是单独的schema,多个schema则是多个yaml文件,yaml文件命名要求是config-xxxx.yaml格式,虽然没有强制要求,但推荐名称中的xxxx与配置的schemaName保持一致,方便维护
dataSources: # 配置数据源列表,必须是有效的jdbc配置,目前仅支持MySQL与PostgreSQL,另外通过一些未公开(代码中可查,但可能会在未来有变化)的变量,可以配置来兼容其他支持JDBC的数据库,但由于没有足够的测试支持,可能会有严重的兼容性问题,配置时候要求至少有一个
master_ds_0: # 数据源名称,可以是合法的字符串,目前的校验规则中,没有强制性要求,只要是合法的yaml字符串即可,但如果要用于分库分表配置,则需要有有意义的标志(在分库分表配置中详述),以下为目前公开的合法配置项目,不包含内部配置参数
# 以下参数为必备参数
url: jdbc:mysql://127.0.0.1:3306/demo_ds_slave_1?serverTimezone=UTC&useSSL=false # 这里的要求合法的jdbc连接串即可,目前尚未兼容MySQL 8.x,需要在maven编译时候,升级MySQL JDBC版本到5.1.46或者47版本(不建议升级到JDBC的8.x系列版本,需要修改源代码,并且无法通过很多测试case)
username: root # MySQL用户名
password: password # MySQL用户的明文密码
# 以下参数为可选参数,给出示例为默认配置,主要用于连接池控制
connectionTimeoutMilliseconds: 30000 #连接超时控制
idleTimeoutMilliseconds: 60000 # 连接空闲时间设置
maxLifetimeMilliseconds: 0 # 连接的最大持有时间,0为无限制
maxPoolSize: 50 # 连接池中最大维持的连接数量
minPoolSize: 1 # 连接池的最小连接数量
maintenanceIntervalMilliseconds: 30000 # 连接维护的时间间隔 atomikos框架需求
# 以下配置的假设是,3307是3306的从库,3309,3310是3308的从库
slave_ds_0:
url: jdbc:mysql://127.0.0.1:3307/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password: password
master_ds_1:
url: jdbc:mysql://127.0.0.1:3308/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password: password
slave_ds_1:
url: jdbc:mysql://127.0.0.1:3309/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password: password
slave_ds_1_slave2:
url: jdbc:mysql://127.0.0.1:3310/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password: password
masterSlaveRule: # 这里配置这个规则的话,相当于是全局读写分离配置
name: ds_rw # 名称,合法的字符串即可,但如果涉及到在读写分离的基础上设置分库分表,则名称需要有意义才可以,另外,虽然目前没有强制要求,但主从库配置需要配置在实际关联的主从库上,如果配置的数据源之间主从是断开的状态,那么可能会发生写入的数据对于只读会话无法读取到的问题
# 如果一个会话发生了写入并且没有提交(显式打开事务),sharidng sphere在后续的路由中,select都会在主库执行,直到会话提交
masterDataSourceName: master_ds_0 # 主库的DataSource名称
slaveDataSourceNames: # 从库的DataSource列表,至少需要有一个
- slave_ds_0
loadBalanceAlgorithmClassName: io.shardingsphere.api.algorithm.masterslave # MasterSlaveLoadBalanceAlgorithm接口的实现类,允许自定义实现 默认提供两个,配置路径为io.shardingsphere.api.algorithm.masterslave下的RandomMasterSlaveLoadBalanceAlgorithm(随机Random)与RoundRobinMasterSlaveLoadBalanceAlgorithm(轮询:次数%从库数量)
loadBalanceAlgorithmType: #从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若loadBalanceAlgorithmClassName存在则忽略该配置,默认为ROUND_ROBIN
shardingRule: # sharding的配置
# 配置主要分两类,一类是对整个sharding规则所有表生效的默认配置,一个是sharing具体某张表时候的配置
# 首先说默认配置
masterSlaveRules: # 在shardingRule中也可以配置shardingRule,对分片生效,具体内容与全局masterSlaveRule一致,但语法为:
master_test_0:
masterDataSourceName: master_ds_0
slaveDataSourceNames:
- slave_ds_0
master_test_1:
masterDataSourceName: master_ds_1
slaveDataSourceNames:
- slave_ds_1
- slave_ds_1_slave2
defaultDataSourceName: master_test_0 # 这里的数据源允许是dataSources的配置项目或者masterSlaveRules配置的名称,配置为masterSlaveRule的话相当于就是配置读写分离了
broadcastTables: # 广播表 这里配置的表列表,对于发生的所有数据变更,都会不经sharidng处理,而是直接发送到所有数据节点,注意此处为列表,每个项目为一个表名称
- broad_1
- broad_2
bindingTables: # 绑定表,也就是实际上哪些配置的sharidng表规则需要实际生效的列表,配置为yaml列表,并且允许单个条目中以逗号切割,所配置表必须已经配置为逻辑表
- sharding_t1
- sharding_t2,sharding_t3
defaultDatabaseShardingStrategy: # 默认库级别sharidng规则,对应代码中ShardingStrategy接口的实现类,目前支持none,inline,hint,complex,standard五种配置 注意此处默认配置仅可以配置五个中的一个
# 规则配置同样适合表sharding配置,同样是在这些算法中选择
none: # 不配置任何规则,SQL会被发给所有节点去执行,这个规则没有子项目可以配置
inline: # 行表达式分片
shardingColumn: test_id # 分片列名称
algorithmExpression: master_test_${test_id % 2} # 分片表达式,根据指定的表达式计算得到需要路由到的数据源名称 需要是合法的groovy表达式,示例配置中,取余为0则语句路由到master_test_0,取余为1则路由到master_test_1
hint: #基于标记的sharding分片
shardingAlgorithm: # 需要是HintShardingAlgorithm接口的实现,目前代码中,仅有为测试目的实现的OrderDatabaseHintShardingAlgorithm,没有生产环境可用的实现
complex: # 支持多列的shariding,目前无生产可用实现
shardingColumns: # 逗号切割的列
shardingAlgorithm: # ComplexKeysShardingAlgorithm接口的实现类
standard: # 单列sharidng算法,需要配合对应的preciseShardingAlgorithm,rangeShardingAlgorithm接口的实现使用,目前无生产可用实现
shardingColumn: # 列名,允许单列
preciseShardingAlgorithm: # preciseShardingAlgorithm接口的实现类
rangeShardingAlgorithm: # rangeShardingAlgorithm接口的实现类
defaultTableStrategy: #配置参考defaultDatabaseShardingStrategy,区别在于,inline算法的配置中,algorithmExpression的配置算法结果需要是实际的物理表名称,而非数据源名称
defaultKeyGenerator: #默认的主键生成算法 如果没有设置,默认为SNOWFLAKE算法
column: # 自增键对应的列名称
type: #自增键的类型,主要用于调用内置的主键生成算法有三个可用值:SNOWFLAKE(时间戳+worker id+自增id),UUID(java.util.UUID类生成的随机UUID),LEAF,其中Snowflake算法与UUID算法已经实现,LEAF目前(2018-01-14)尚未实现
className: # 非内置的其他实现了KeyGenerator接口的类,需要注意,如果设置这个,就不能设置type,否则type的设置会覆盖class的设置
props:
# 定制算法需要设置的参数,比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds
tables: #配置表sharding的主要位置
sharding_t1:
actualDataNodes: master_test_${0..1}.t_order${0..1} # sharidng 表对应的数据源以及物理名称,需要用表达式处理,表示表实际上在哪些数据源存在,配置示例中,意思是总共存在4个分片master_test_0.t_order0,master_test_0.t_order1,master_test_1.t_order0,master_test_1.t_order1
# 需要注意的是,必须保证设置databaseStrategy可以路由到唯一的dataSource,tableStrategy可以路由到dataSource中唯一的物理表上,否则可能导致错误:一个insert语句被插入到多个实际物理表中
databaseStrategy: # 局部设置会覆盖全局设置,参考defaultDatabaseShardingStrategy
tableStrategy: # 局部设置会覆盖全局设置,参考defaultTableStrategy
keyGenerator: # 局部设置会覆盖全局设置,参考defaultKeyGenerator
logicIndex: # 逻辑索引名称 由于Oracle,PG这种数据库中,索引与表共用命名空间,如果接受到drop index语句,执行之前,会通过这个名称配置的确定对应的实际物理表名称
props:
sql.show: #是否开启SQL显示,默认值: false
acceptor.size: # accept连接的线程数量,默认为cpu核数2倍
executor.size: #工作线程数量最大,默认值: 无限制
max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1
proxy.frontend.flush.threshold: # proxy的服务时候,对于单个大查询,每多少个网络包返回一次
check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false
proxy.transaction.type: # 默认LOCAL,proxy的事务模型 允许LOCAL,XA,BASE三个值 LOCAL无分布式事务,XA则是采用atomikos实现的分布式事务 BASE目前尚未实现
proxy.opentracing.enabled: # 是否启用opentracing
proxy.backend.use.nio: # 是否采用netty的NIO机制连接后端数据库,默认False ,使用epoll机制
proxy.backend.max.connections: # 使用NIO而非epoll的话,proxy后台连接每个netty客户端允许的最大连接数量(注意不是数据库连接限制) 默认为8
proxy.backend.connection.timeout.seconds: #使用nio而非epoll的话,proxy后台连接的超时时间,默认60s
check.table.metadata.enabled: # 是否在启动时候,检查sharing的表的实际元数据是否一致,默认False
configMap: #用户自定义配置
key1: value1
key2: value2
keyx: valuex
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
读写分离
dataSources: #省略数据源配置,与数据分片一致
masterSlaveRule:
name: #读写分离数据源名称
masterDataSourceName: #主库数据源名称
slaveDataSourceNames: #从库数据源名称列表
- <data_source_name1>
- <data_source_name2>
- <data_source_name_x>
loadBalanceAlgorithmClassName: #从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器
loadBalanceAlgorithmType: #从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若`loadBalanceAlgorithmClassName`存在则忽略该配置
props: #属性配置
sql.show: #是否开启SQL显示,默认值: false
executor.size: #工作线程数量,默认值: CPU核数
check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false
configMap: #用户自定义配置
key1: value1
key2: value2
keyx: valuex
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
数据治理
dataSources: #省略数据源配置
shardingRule: #省略分片规则配置
masterSlaveRule: #省略读写分离规则配置
orchestration:
name: #数据治理实例名称
overwrite: #本地配置是否覆盖注册中心配置。如果可覆盖,每次启动都以本地配置为准
registry: #注册中心配置
serverLists: #连接注册中心服务器的列表。包括IP地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181
namespace: #注册中心的命名空间
digest: #连接注册中心的权限令牌。缺省为不需要权限验证
operationTimeoutMilliseconds: #操作超时的毫秒数,默认500毫秒
maxRetries: #连接失败后的最大重试次数,默认3次
retryIntervalMilliseconds: #重试间隔毫秒数,默认500毫秒
timeToLiveSeconds: #临时节点存活秒数,默认60秒
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Yaml语法说明
!! 表示实例化该类
- 表示可以包含一个或多个
[] 表示数组,可以与减号相互替换使用
# SpringBoot配置
注意事项
行表达式标识符可以使用${...}或$->{...},但前者与Spring本身的属性文件占位符冲突,因此在Spring环境中使用行表达式标识符建议使用$->{...}。
配置示例
数据分片
sharding.jdbc.datasource.names=ds0,ds1
sharding.jdbc.datasource.ds0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=
sharding.jdbc.datasource.ds1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
读写分离
sharding.jdbc.datasource.names=master,slave0,slave1
sharding.jdbc.datasource.master.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master.url=jdbc:mysql://localhost:3306/master
sharding.jdbc.datasource.master.username=root
sharding.jdbc.datasource.master.password=
sharding.jdbc.datasource.slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.slave0.url=jdbc:mysql://localhost:3306/slave0
sharding.jdbc.datasource.slave0.username=root
sharding.jdbc.datasource.slave0.password=
sharding.jdbc.datasource.slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.slave1.url=jdbc:mysql://localhost:3306/slave1
sharding.jdbc.datasource.slave1.username=root
sharding.jdbc.datasource.slave1.password=
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
sharding.jdbc.config.masterslave.name=ms
sharding.jdbc.config.masterslave.master-data-source-name=master
sharding.jdbc.config.masterslave.slave-data-source-names=slave0,slave1
sharding.jdbc.config.props.sql.show=true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
数据分片 + 读写分离
sharding.jdbc.datasource.names=master0,master1,master0slave0,master0slave1,master1slave0,master1slave1
sharding.jdbc.datasource.master0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0.url=jdbc:mysql://localhost:3306/master0
sharding.jdbc.datasource.master0.username=root
sharding.jdbc.datasource.master0.password=
sharding.jdbc.datasource.master0slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave0.url=jdbc:mysql://localhost:3306/master0slave0
sharding.jdbc.datasource.master0slave0.username=root
sharding.jdbc.datasource.master0slave0.password=
sharding.jdbc.datasource.master0slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave1.url=jdbc:mysql://localhost:3306/master0slave1
sharding.jdbc.datasource.master0slave1.username=root
sharding.jdbc.datasource.master0slave1.password=
sharding.jdbc.datasource.master1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1.url=jdbc:mysql://localhost:3306/master1
sharding.jdbc.datasource.master1.username=root
sharding.jdbc.datasource.master1.password=
sharding.jdbc.datasource.master1slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave0.url=jdbc:mysql://localhost:3306/master1slave0
sharding.jdbc.datasource.master1slave0.username=root
sharding.jdbc.datasource.master1slave0.password=
sharding.jdbc.datasource.master1slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave1.url=jdbc:mysql://localhost:3306/master1slave1
sharding.jdbc.datasource.master1slave1.username=root
sharding.jdbc.datasource.master1slave1.password=
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=master$->{user_id % 2}
sharding.jdbc.config.sharding.master-slave-rules.ds0.master-data-source-name=master0
sharding.jdbc.config.sharding.master-slave-rules.ds0.slave-data-source-names=master0slave0, master0slave1
sharding.jdbc.config.sharding.master-slave-rules.ds1.master-data-source-name=master1
sharding.jdbc.config.sharding.master-slave-rules.ds1.slave-data-source-names=master1slave0, master1slave1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
数据治理
sharding.jdbc.datasource.names=ds,ds0,ds1
sharding.jdbc.datasource.ds.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds.driver-class-name=org.h2.Driver
sharding.jdbc.datasource.ds.url=jdbc:mysql://localhost:3306/ds
sharding.jdbc.datasource.ds.username=root
sharding.jdbc.datasource.ds.password=
sharding.jdbc.datasource.ds0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=
sharding.jdbc.datasource.ds1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=
sharding.jdbc.config.sharding.default-data-source-name=ds
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=master$->{user_id % 2}
sharding.jdbc.config.orchestration.name=spring_boot_ds_sharding
sharding.jdbc.config.orchestration.overwrite=true
sharding.jdbc.config.orchestration.registry.namespace=orchestration-spring-boot-sharding-test
sharding.jdbc.config.orchestration.registry.server-lists=localhost:2181
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
配置项说明
数据分片
sharding.jdbc.datasource.names= #数据源名称,多数据源以逗号分隔
sharding.jdbc.datasource.<data-source-name>.type= #数据库连接池类名称
sharding.jdbc.datasource.<data-source-name>.driver-class-name= #数据库驱动类名
sharding.jdbc.datasource.<data-source-name>.url= #数据库url连接
sharding.jdbc.datasource.<data-source-name>.username= #数据库用户名
sharding.jdbc.datasource.<data-source-name>.password= #数据库密码
sharding.jdbc.datasource.<data-source-name>.xxx= #数据库连接池的其它属性
sharding.jdbc.config.sharding.tables.<logic-table-name>.actual-data-nodes= #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点。用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
#分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
#用于单分片键的标准分片场景
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= #分片列名称
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= #精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= #范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器
#用于多分片键的复合分片场景
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= #分片列名称,多个列以逗号分隔
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器
#行表达式分片策略
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= #分片列名称
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= #分片算法行表达式,需符合groovy语法
#Hint分片策略
sharding.jdbc.config.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器
#分表策略,同分库策略
sharding.jdbc.config.sharding.tables.<logic-table-name>.table-strategy.xxx= #省略
sharding.jdbc.config.sharding.tables.<logic-table-name>.key-generator-column-name= #自增列名称,缺省表示不使用自增主键生成器
sharding.jdbc.config.sharding.tables.<logic-table-name>.key-generator-class-name= #自增列值生成器类名称,缺省表示使用默认自增列值生成器。该类需提供无参数的构造器
sharding.jdbc.config.sharding.tables.<logic-table-name>.logic-index= #逻辑索引名称,对于分表的Oracle/PostgreSQL数据库中DROP INDEX XXX语句,需要通过配置逻辑索引名称定位所执行SQL的真实分表
sharding.jdbc.config.sharding.binding-tables[0]= #绑定表规则列表
sharding.jdbc.config.sharding.binding-tables[1]= #绑定表规则列表
sharding.jdbc.config.sharding.binding-tables[x]= #绑定表规则列表
sharding.jdbc.config.sharding.broadcast-tables[0]= #广播表规则列表
sharding.jdbc.config.sharding.broadcast-tables[1]= #广播表规则列表
sharding.jdbc.config.sharding.broadcast-tables[x]= #广播表规则列表
sharding.jdbc.config.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位
sharding.jdbc.config.sharding.default-database-strategy.xxx= #默认数据库分片策略,同分库策略
sharding.jdbc.config.sharding.default-table-strategy.xxx= #默认表分片策略,同分表策略
sharding.jdbc.config.sharding.default-key-generator-class-name= #默认自增列值生成器类名称,缺省使用io.shardingsphere.core.keygen.DefaultKeyGenerator。该类需实现KeyGenerator接口并提供无参数的构造器
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= #详见读写分离部分
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= #详见读写分离部分
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= #详见读写分离部分
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= #详见读写分离部分
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= #详见读写分离部分
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= #详见读写分离部分
sharding.jdbc.config.config.map.key1= #详见读写分离部分
sharding.jdbc.config.config.map.key2= #详见读写分离部分
sharding.jdbc.config.config.map.keyx= #详见读写分离部分
sharding.jdbc.config.props.sql.show= #是否开启SQL显示,默认值: false
sharding.jdbc.config.props.executor.size= #工作线程数量,默认值: CPU核数
sharding.jdbc.config.config.map.key1= #用户自定义配置
sharding.jdbc.config.config.map.key2= #用户自定义配置
sharding.jdbc.config.config.map.keyx= #用户自定义配置
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
读写分离
#省略数据源配置,与数据分片一致
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= #主库数据源名称
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= #从库数据源名称列表
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= #从库数据源名称列表
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= #从库数据源名称列表
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= #从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器
sharding.jdbc.config.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= #从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若`load-balance-algorithm-class-name`存在则忽略该配置
sharding.jdbc.config.config.map.key1= #用户自定义配置
sharding.jdbc.config.config.map.key2= #用户自定义配置
sharding.jdbc.config.config.map.keyx= #用户自定义配置
sharding.jdbc.config.props.sql.show= #是否开启SQL显示,默认值: false
sharding.jdbc.config.props.executor.size= #工作线程数量,默认值: CPU核数
sharding.jdbc.config.props.check.table.metadata.enabled= #是否在启动时检查分表元数据一致性,默认值: false
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
数据治理
#省略数据源、数据分片和读写分离配置
sharding.jdbc.config.sharding.orchestration.name= #数据治理实例名称
sharding.jdbc.config.sharding.orchestration.overwrite= #本地配置是否覆盖注册中心配置。如果可覆盖,每次启动都以本地配置为准
sharding.jdbc.config.sharding.orchestration.registry.server-lists= #连接注册中心服务器的列表。包括IP地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181
sharding.jdbc.config.sharding.orchestration.registry.namespace= #注册中心的命名空间
sharding.jdbc.config.sharding.orchestration.registry.digest= #连接注册中心的权限令牌。缺省为不需要权限验证
sharding.jdbc.config.sharding.orchestration.registry.operation-timeout-milliseconds= #操作超时的毫秒数,默认500毫秒
sharding.jdbc.config.sharding.orchestration.registry.max-retries= #连接失败后的最大重试次数,默认3次
sharding.jdbc.config.sharding.orchestration.registry.retry-interval-milliseconds= #重试间隔毫秒数,默认500毫秒
sharding.jdbc.config.sharding.orchestration.registry.time-to-live-seconds= #临时节点存活秒数,默认60秒
2
3
4
5
6
7
8
9
10
11
# 日志分表
1、ruoyi-system/pom.xml添加maven依赖
<!-- ShardingSphere 读写分离/分库分表 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>
2
3
4
5
6
2、我们将操作日志sys_oper_log表根据http请求进行分表存储
drop table if exists sys_oper_log_get;
create table sys_oper_log_get (
oper_id bigint(20) not null auto_increment comment '日志主键',
title varchar(50) default '' comment '模块标题',
business_type int(2) default 0 comment '业务类型(0其它 1新增 2修改 3删除)',
method varchar(100) default '' comment '方法名称',
request_method varchar(10) default '' comment '请求方式',
operator_type int(1) default 0 comment '操作类别(0其它 1后台用户 2手机端用户)',
oper_name varchar(50) default '' comment '操作人员',
dept_name varchar(50) default '' comment '部门名称',
oper_url varchar(255) default '' comment '请求URL',
oper_ip varchar(128) default '' comment '主机地址',
oper_location varchar(255) default '' comment '操作地点',
oper_param varchar(2000) default '' comment '请求参数',
json_result varchar(2000) default '' comment '返回参数',
status int(1) default 0 comment '操作状态(0正常 1异常)',
error_msg varchar(2000) default '' comment '错误消息',
oper_time datetime comment '操作时间',
primary key (oper_id)
) engine=innodb auto_increment=100 comment = 'get操作日志记录';
drop table if exists sys_oper_log_post;
create table sys_oper_log_post (
oper_id bigint(20) not null auto_increment comment '日志主键',
title varchar(50) default '' comment '模块标题',
business_type int(2) default 0 comment '业务类型(0其它 1新增 2修改 3删除)',
method varchar(100) default '' comment '方法名称',
request_method varchar(10) default '' comment '请求方式',
operator_type int(1) default 0 comment '操作类别(0其它 1后台用户 2手机端用户)',
oper_name varchar(50) default '' comment '操作人员',
dept_name varchar(50) default '' comment '部门名称',
oper_url varchar(255) default '' comment '请求URL',
oper_ip varchar(128) default '' comment '主机地址',
oper_location varchar(255) default '' comment '操作地点',
oper_param varchar(2000) default '' comment '请求参数',
json_result varchar(2000) default '' comment '返回参数',
status int(1) default 0 comment '操作状态(0正常 1异常)',
error_msg varchar(2000) default '' comment '错误消息',
oper_time datetime comment '操作时间',
primary key (oper_id)
) engine=innodb auto_increment=100 comment = 'post操作日志记录';
drop table if exists sys_oper_log_put;
create table sys_oper_log_put (
oper_id bigint(20) not null auto_increment comment '日志主键',
title varchar(50) default '' comment '模块标题',
business_type int(2) default 0 comment '业务类型(0其它 1新增 2修改 3删除)',
method varchar(100) default '' comment '方法名称',
request_method varchar(10) default '' comment '请求方式',
operator_type int(1) default 0 comment '操作类别(0其它 1后台用户 2手机端用户)',
oper_name varchar(50) default '' comment '操作人员',
dept_name varchar(50) default '' comment '部门名称',
oper_url varchar(255) default '' comment '请求URL',
oper_ip varchar(128) default '' comment '主机地址',
oper_location varchar(255) default '' comment '操作地点',
oper_param varchar(2000) default '' comment '请求参数',
json_result varchar(2000) default '' comment '返回参数',
status int(1) default 0 comment '操作状态(0正常 1异常)',
error_msg varchar(2000) default '' comment '错误消息',
oper_time datetime comment '操作时间',
primary key (oper_id)
) engine=innodb auto_increment=100 comment = 'put操作日志记录';
drop table if exists sys_oper_log_delete;
create table sys_oper_log_delete (
oper_id bigint(20) not null auto_increment comment '日志主键',
title varchar(50) default '' comment '模块标题',
business_type int(2) default 0 comment '业务类型(0其它 1新增 2修改 3删除)',
method varchar(100) default '' comment '方法名称',
request_method varchar(10) default '' comment '请求方式',
operator_type int(1) default 0 comment '操作类别(0其它 1后台用户 2手机端用户)',
oper_name varchar(50) default '' comment '操作人员',
dept_name varchar(50) default '' comment '部门名称',
oper_url varchar(255) default '' comment '请求URL',
oper_ip varchar(128) default '' comment '主机地址',
oper_location varchar(255) default '' comment '操作地点',
oper_param varchar(2000) default '' comment '请求参数',
json_result varchar(2000) default '' comment '返回参数',
status int(1) default 0 comment '操作状态(0正常 1异常)',
error_msg varchar(2000) default '' comment '错误消息',
oper_time datetime comment '操作时间',
primary key (oper_id)
) engine=innodb auto_increment=100 comment = 'delete操作日志记录';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
3、在nacos中修改ruoyi-system,增加shardingsphere配置
# spring配置
spring:
redis:
host: localhost
port: 6379
password:
# 分库分表配置
shardingsphere:
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
username: root
password: password
jdbc-url: jdbc:mysql://localhost:3306/ry-cloud?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
names: ds0
props:
sql-show: true
rules:
sharding:
sharding-algorithms:
table-inline:
props:
algorithm-expression: sys_oper_log_$->{request_method}
type: INLINE
tables:
sys_oper_log:
actual-data-nodes: ds0.sys_oper_log_GET,ds0.sys_oper_log_POST,ds0.sys_oper_log_PUT,ds0.sys_oper_log_DELETE
table-strategy:
standard:
sharding-algorithm-name: table-inline
sharding-column: request_method
# mybatis配置
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.ruoyi.system
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath:mapper/**/*.xml
# swagger配置
swagger:
title: 系统模块接口文档
license: Powered By ruoyi
licenseUrl: https://ruoyi.vip
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
4、删除ruoyi-modules-system/pom.xml中的ruoyi-common-datasource多数据源配置依赖
由于shardingsphere和dynamic-datasource冲突,这里测试我们先移除ruoyi-common-datasource多数据模块。
5、编写测试类TestOperlogController.java
package com.ruoyi.system.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.ruoyi.common.core.web.controller.BaseController;
import com.ruoyi.common.core.web.domain.AjaxResult;
import com.ruoyi.system.api.domain.SysOperLog;
import com.ruoyi.system.service.ISysOperLogService;
@RestController
@RequestMapping("/test/operlog")
public class TestOperlogController extends BaseController
{
@Autowired
private ISysOperLogService operLogService;
@GetMapping("/{method}")
public AjaxResult operlog(@PathVariable("method") String method)
{
SysOperLog operLog = new SysOperLog();
operLog.setTitle("测试数据");
operLog.setOperName("admin");
operLog.setRequestMethod(method);
return toAjax(operLogService.insertOperlog(operLog));
}
@GetMapping("/list")
public AjaxResult list()
{
return AjaxResult.success(operLogService.selectOperLogList(new SysOperLog()));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
6、启动系统服务RuoYiSystemApplication.java测试验证
访问 http://localhost:9201/test/operlog/GET (opens new window) 入到sys_oper_log_get表
访问 http://localhost:9201/test/operlog/POST (opens new window) 入到sys_oper_log_post表
访问 http://localhost:9201/test/operlog/PUT (opens new window) 入到sys_oper_log_put表
访问 http://localhost:9201/test/operlog/DELETE (opens new window) 入到sys_oper_log_delete表
查询 http://localhost:9201/test/operlog/list (opens new window)
请求接口会设置值到request_method属性去匹配algorithm-expression规则。
后端接口Controller如果使用了@Log注解也会自动匹配到对应的表。
注意
由于shardingsphere和dynamic-datasource冲突,所以需要移除ruoyi-common-datasource模块,如果想要这两个模块同时都存在,可以看下一个章节-集成多数据源。
# 集成多数据源
如果有分库分表,又有切换数据源的需求可以使用多数据源dynamic-datasource与shardingsphere集成的场景方案。
1、ruoyi-system/pom.xml添加maven依赖
<!-- ShardingSphere 读写分离/分库分表 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>
2
3
4
5
6
2、分别配置shardingjdbc和多数据源
# spring配置
spring:
redis:
host: localhost
port: 6379
password:
# 分库分表配置
shardingsphere:
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
username: root
password: password
jdbc-url: jdbc:mysql://localhost:3306/ry-log?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
names: ds0
props:
sql-show: true
rules:
sharding:
sharding-algorithms:
table-inline:
props:
algorithm-expression: sys_oper_log_$->{request_method}
type: INLINE
tables:
sys_oper_log:
actual-data-nodes: ds0.sys_oper_log_GET,ds0.sys_oper_log_POST,ds0.sys_oper_log_PUT,ds0.sys_oper_log_DELETE
table-strategy:
standard:
sharding-algorithm-name: table-inline
sharding-column: request_method
# 动态数据源配置
datasource:
dynamic:
datasource:
master:
username: root
password: password
url: jdbc:mysql://localhost:3306/ry-cloud?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
driver-class-name: com.mysql.cj.jdbc.Driver
order:
username: root
password: password
url: jdbc:mysql://localhost:3306/ry-order?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
driver-class-name: com.mysql.cj.jdbc.Driver
# mybatis配置
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.ruoyi.system
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath:mapper/**/*.xml
# swagger配置
swagger:
title: 系统模块接口文档
license: Powered By ruoyi
licenseUrl: https://ruoyi.vip
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
3、添加一个多数据测试库ry-order和表sys_order
DROP DATABASE IF EXISTS `ry-order`;
CREATE DATABASE `ry-order` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
USE `ry-order`;
-- ----------------------------
-- 订单信息表sys_order
-- ----------------------------
DROP TABLE IF EXISTS sys_order;
CREATE TABLE sys_order
(
order_id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '订单ID',
user_id BIGINT(64) NOT NULL COMMENT '用户编号',
STATUS CHAR(1) NOT NULL COMMENT '状态(0交易成功 1交易失败)',
order_no VARCHAR(64) DEFAULT NULL COMMENT '订单流水',
PRIMARY KEY (order_id)
) ENGINE=INNODB COMMENT = '订单信息表';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
4、添加sys_order测试代码
SysOrder.java
package com.ruoyi.system.domain;
import com.ruoyi.common.core.web.domain.BaseEntity;
/**
* 订单对象 tb_order
*
* @author ruoyi
*/
public class SysOrder extends BaseEntity
{
private static final long serialVersionUID = 1L;
/** 订单编号 */
private Long orderId;
/** 用户编号 */
private Long userId;
/** 状态 */
private String status;
/** 订单编号 */
private String orderNo;
public void setOrderId(Long orderId)
{
this.orderId = orderId;
}
public Long getOrderId()
{
return orderId;
}
public void setUserId(Long userId)
{
this.userId = userId;
}
public Long getUserId()
{
return userId;
}
public void setStatus(String status)
{
this.status = status;
}
public String getStatus()
{
return status;
}
public void setOrderNo(String orderNo)
{
this.orderNo = orderNo;
}
public String getOrderNo()
{
return orderNo;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
SysOrderMapper.java
package com.ruoyi.system.mapper;
import java.util.List;
import com.ruoyi.system.domain.SysOrder;
/**
* 订单Mapper接口
*
* @author ruoyi
*/
public interface SysOrderMapper
{
/**
* 查询订单
*
* @param orderId 订单编号
* @return 订单信息
*/
public SysOrder selectSysOrderById(Long orderId);
/**
* 查询订单列表
*
* @param sysOrder 订单信息
* @return 订单列表
*/
public List<SysOrder> selectSysOrderList(SysOrder sysOrder);
/**
* 新增订单
*
* @param sysOrder 订单
* @return 结果
*/
public int insertSysOrder(SysOrder sysOrder);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
ISysOrderService.java
package com.ruoyi.system.service;
import java.util.List;
import com.ruoyi.system.domain.SysOrder;
/**
* 订单Service接口
*
* @author ruoyi
*/
public interface ISysOrderService
{
/**
* 查询订单
*
* @param orderId 订单编号
* @return 订单信息
*/
public SysOrder selectSysOrderById(Long orderId);
/**
* 查询订单列表
*
* @param sysOrder 订单信息
* @return 订单列表
*/
public List<SysOrder> selectSysOrderList(SysOrder sysOrder);
/**
* 新增订单
*
* @param sysOrder 订单
* @return 结果
*/
public int insertSysOrder(SysOrder sysOrder);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
SysOrderServiceImpl.java
package com.ruoyi.system.service.impl;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.baomidou.dynamic.datasource.annotation.DS;
import com.ruoyi.system.domain.SysOrder;
import com.ruoyi.system.mapper.SysOrderMapper;
import com.ruoyi.system.service.ISysOrderService;
/**
* 订单Service业务层处理
*
* @author ruoyi
*/
@Service
public class SysOrderServiceImpl implements ISysOrderService
{
@Autowired
private SysOrderMapper myShardingMapper;
/**
* 查询订单
*
* @param orderId 订单编号
* @return 订单信息
*/
@Override
@DS("order")
public SysOrder selectSysOrderById(Long orderId)
{
return myShardingMapper.selectSysOrderById(orderId);
}
/**
* 查询订单列表
*
* @param sysOrder 订单信息
* @return 订单列表
*/
@Override
@DS("order")
public List<SysOrder> selectSysOrderList(SysOrder sysOrder)
{
return myShardingMapper.selectSysOrderList(sysOrder);
}
/**
* 新增订单
*
* @param sysOrder 订单
* @return 结果
*/
@Override
@DS("order")
public int insertSysOrder(SysOrder sysOrder)
{
return myShardingMapper.insertSysOrder(sysOrder);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
SysOrderController.java
package com.ruoyi.system.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.ruoyi.common.core.utils.uuid.IdUtils;
import com.ruoyi.common.core.web.controller.BaseController;
import com.ruoyi.common.core.web.domain.AjaxResult;
import com.ruoyi.system.domain.SysOrder;
import com.ruoyi.system.service.ISysOrderService;
/**
* 订单 Controller
*
* @author ruoyi
*/
@RestController
@RequestMapping("/order")
public class SysOrderController extends BaseController
{
@Autowired
private ISysOrderService sysOrderService;
@GetMapping("/add/{userId}")
public AjaxResult add(@PathVariable("userId") Long userId)
{
SysOrder sysOrder = new SysOrder();
sysOrder.setUserId(userId);
sysOrder.setStatus("0");
sysOrder.setOrderNo(IdUtils.fastSimpleUUID());
return AjaxResult.success(sysOrderService.insertSysOrder(sysOrder));
}
@GetMapping("/list")
public AjaxResult list(SysOrder sysOrder)
{
return AjaxResult.success(sysOrderService.selectSysOrderList(sysOrder));
}
@GetMapping("/query/{orderId}")
public AjaxResult query(@PathVariable("orderId") Long orderId)
{
return AjaxResult.success(sysOrderService.selectSysOrderById(orderId));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
SysOrderMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ruoyi.system.mapper.SysOrderMapper">
<resultMap type="SysOrder" id="SysOrderResult">
<result property="orderId" column="order_id" />
<result property="userId" column="user_id" />
<result property="status" column="status" />
<result property="orderNo" column="order_no" />
</resultMap>
<sql id="selectSysOrderVo">
select order_id, user_id, status, order_no from sys_order
</sql>
<select id="selectSysOrderList" parameterType="SysOrder" resultMap="SysOrderResult">
<include refid="selectSysOrderVo"/>
</select>
<select id="selectSysOrderById" parameterType="Long" resultMap="SysOrderResult">
<include refid="selectSysOrderVo"/>
where order_id = #{orderId}
</select>
<insert id="insertSysOrder" parameterType="SysOrder">
insert into sys_order
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="orderId != null">order_id,</if>
<if test="userId != null">user_id,</if>
<if test="status != null">status,</if>
<if test="orderNo != null">order_no,</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="orderId != null">#{orderId},</if>
<if test="userId != null">#{userId},</if>
<if test="status != null">#{status},</if>
<if test="orderNo != null">#{orderNo},</if>
</trim>
</insert>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
5、新增动态数据源配置DataSourceConfiguration.java
package com.ruoyi.system.config;
import java.util.Map;
import javax.annotation.Resource;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import com.baomidou.dynamic.datasource.DynamicRoutingDataSource;
import com.baomidou.dynamic.datasource.provider.AbstractDataSourceProvider;
import com.baomidou.dynamic.datasource.provider.DynamicDataSourceProvider;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DataSourceProperty;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceProperties;
/**
* 动态数据源配置
*
* @author ruoyi
*/
@Configuration
public class DataSourceConfiguration
{
/**
* 分表数据源名称
*/
private static final String SHARDING_DATA_SOURCE_NAME = "sharding";
/**
* 动态数据源配置项
*/
@Autowired
private DynamicDataSourceProperties properties;
/**
* shardingjdbc有四种数据源,需要根据业务注入不同的数据源
*
* <p>1. 未使用分片, 脱敏的名称(默认): shardingDataSource;
* <p>2. 主从数据源: masterSlaveDataSource;
* <p>3. 脱敏数据源:encryptDataSource;
* <p>4. 影子数据源:shadowDataSource
*
*/
@Resource
private DataSource shardingSphereDataSource;
@Bean
public DynamicDataSourceProvider dynamicDataSourceProvider()
{
Map<String, DataSourceProperty> datasourceMap = properties.getDatasource();
return new AbstractDataSourceProvider()
{
@Override
public Map<String, DataSource> loadDataSources()
{
Map<String, DataSource> dataSourceMap = createDataSourceMap(datasourceMap);
// 将 shardingjdbc 管理的数据源也交给动态数据源管理
dataSourceMap.put(SHARDING_DATA_SOURCE_NAME, shardingSphereDataSource);
return dataSourceMap;
}
};
}
/**
* 将动态数据源设置为首选的
* 当spring存在多个数据源时, 自动注入的是首选的对象
* 设置为主要的数据源之后,就可以支持shardingjdbc原生的配置方式了
*/
@Primary
@Bean
public DataSource dataSource()
{
DynamicRoutingDataSource dataSource = new DynamicRoutingDataSource();
dataSource.setPrimary(properties.getPrimary());
dataSource.setStrict(properties.getStrict());
dataSource.setStrategy(properties.getStrategy());
dataSource.setP6spy(properties.getP6spy());
dataSource.setSeata(properties.getSeata());
return dataSource;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
6、新增ry-log数据库和sys_oper_log_xxx四张表
DROP DATABASE IF EXISTS `ry-log`;
CREATE DATABASE `ry-log` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
USE `ry-log`;
DROP TABLE IF EXISTS sys_oper_log_get;
CREATE TABLE sys_oper_log_get (
oper_id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '日志主键',
title VARCHAR(50) DEFAULT '' COMMENT '模块标题',
business_type INT(2) DEFAULT 0 COMMENT '业务类型(0其它 1新增 2修改 3删除)',
method VARCHAR(100) DEFAULT '' COMMENT '方法名称',
request_method VARCHAR(10) DEFAULT '' COMMENT '请求方式',
operator_type INT(1) DEFAULT 0 COMMENT '操作类别(0其它 1后台用户 2手机端用户)',
oper_name VARCHAR(50) DEFAULT '' COMMENT '操作人员',
dept_name VARCHAR(50) DEFAULT '' COMMENT '部门名称',
oper_url VARCHAR(255) DEFAULT '' COMMENT '请求URL',
oper_ip VARCHAR(128) DEFAULT '' COMMENT '主机地址',
oper_location VARCHAR(255) DEFAULT '' COMMENT '操作地点',
oper_param VARCHAR(2000) DEFAULT '' COMMENT '请求参数',
json_result VARCHAR(2000) DEFAULT '' COMMENT '返回参数',
STATUS INT(1) DEFAULT 0 COMMENT '操作状态(0正常 1异常)',
error_msg VARCHAR(2000) DEFAULT '' COMMENT '错误消息',
oper_time DATETIME COMMENT '操作时间',
PRIMARY KEY (oper_id)
) ENGINE=INNODB AUTO_INCREMENT=100 COMMENT = 'get操作日志记录';
DROP TABLE IF EXISTS sys_oper_log_post;
CREATE TABLE sys_oper_log_post (
oper_id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '日志主键',
title VARCHAR(50) DEFAULT '' COMMENT '模块标题',
business_type INT(2) DEFAULT 0 COMMENT '业务类型(0其它 1新增 2修改 3删除)',
method VARCHAR(100) DEFAULT '' COMMENT '方法名称',
request_method VARCHAR(10) DEFAULT '' COMMENT '请求方式',
operator_type INT(1) DEFAULT 0 COMMENT '操作类别(0其它 1后台用户 2手机端用户)',
oper_name VARCHAR(50) DEFAULT '' COMMENT '操作人员',
dept_name VARCHAR(50) DEFAULT '' COMMENT '部门名称',
oper_url VARCHAR(255) DEFAULT '' COMMENT '请求URL',
oper_ip VARCHAR(128) DEFAULT '' COMMENT '主机地址',
oper_location VARCHAR(255) DEFAULT '' COMMENT '操作地点',
oper_param VARCHAR(2000) DEFAULT '' COMMENT '请求参数',
json_result VARCHAR(2000) DEFAULT '' COMMENT '返回参数',
STATUS INT(1) DEFAULT 0 COMMENT '操作状态(0正常 1异常)',
error_msg VARCHAR(2000) DEFAULT '' COMMENT '错误消息',
oper_time DATETIME COMMENT '操作时间',
PRIMARY KEY (oper_id)
) ENGINE=INNODB AUTO_INCREMENT=100 COMMENT = 'post操作日志记录';
DROP TABLE IF EXISTS sys_oper_log_put;
CREATE TABLE sys_oper_log_put (
oper_id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '日志主键',
title VARCHAR(50) DEFAULT '' COMMENT '模块标题',
business_type INT(2) DEFAULT 0 COMMENT '业务类型(0其它 1新增 2修改 3删除)',
method VARCHAR(100) DEFAULT '' COMMENT '方法名称',
request_method VARCHAR(10) DEFAULT '' COMMENT '请求方式',
operator_type INT(1) DEFAULT 0 COMMENT '操作类别(0其它 1后台用户 2手机端用户)',
oper_name VARCHAR(50) DEFAULT '' COMMENT '操作人员',
dept_name VARCHAR(50) DEFAULT '' COMMENT '部门名称',
oper_url VARCHAR(255) DEFAULT '' COMMENT '请求URL',
oper_ip VARCHAR(128) DEFAULT '' COMMENT '主机地址',
oper_location VARCHAR(255) DEFAULT '' COMMENT '操作地点',
oper_param VARCHAR(2000) DEFAULT '' COMMENT '请求参数',
json_result VARCHAR(2000) DEFAULT '' COMMENT '返回参数',
STATUS INT(1) DEFAULT 0 COMMENT '操作状态(0正常 1异常)',
error_msg VARCHAR(2000) DEFAULT '' COMMENT '错误消息',
oper_time DATETIME COMMENT '操作时间',
PRIMARY KEY (oper_id)
) ENGINE=INNODB AUTO_INCREMENT=100 COMMENT = 'put操作日志记录';
DROP TABLE IF EXISTS sys_oper_log_delete;
CREATE TABLE sys_oper_log_delete (
oper_id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '日志主键',
title VARCHAR(50) DEFAULT '' COMMENT '模块标题',
business_type INT(2) DEFAULT 0 COMMENT '业务类型(0其它 1新增 2修改 3删除)',
method VARCHAR(100) DEFAULT '' COMMENT '方法名称',
request_method VARCHAR(10) DEFAULT '' COMMENT '请求方式',
operator_type INT(1) DEFAULT 0 COMMENT '操作类别(0其它 1后台用户 2手机端用户)',
oper_name VARCHAR(50) DEFAULT '' COMMENT '操作人员',
dept_name VARCHAR(50) DEFAULT '' COMMENT '部门名称',
oper_url VARCHAR(255) DEFAULT '' COMMENT '请求URL',
oper_ip VARCHAR(128) DEFAULT '' COMMENT '主机地址',
oper_location VARCHAR(255) DEFAULT '' COMMENT '操作地点',
oper_param VARCHAR(2000) DEFAULT '' COMMENT '请求参数',
json_result VARCHAR(2000) DEFAULT '' COMMENT '返回参数',
STATUS INT(1) DEFAULT 0 COMMENT '操作状态(0正常 1异常)',
error_msg VARCHAR(2000) DEFAULT '' COMMENT '错误消息',
oper_time DATETIME COMMENT '操作时间',
PRIMARY KEY (oper_id)
) ENGINE=INNODB AUTO_INCREMENT=100 COMMENT = 'delete操作日志记录';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
7、修改SysOperLogServiceImpl.java,切换分库分表
package com.ruoyi.system.service.impl;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.baomidou.dynamic.datasource.annotation.DS;
import com.ruoyi.system.api.domain.SysOperLog;
import com.ruoyi.system.mapper.SysOperLogMapper;
import com.ruoyi.system.service.ISysOperLogService;
/**
* 操作日志 服务层处理
*
* @author ruoyi
*/
@Service
public class SysOperLogServiceImpl implements ISysOperLogService
{
@Autowired
private SysOperLogMapper operLogMapper;
/**
* 新增操作日志
*
* @param operLog 操作日志对象
* @return 结果
*/
@Override
@DS("sharding")
public int insertOperlog(SysOperLog operLog)
{
return operLogMapper.insertOperlog(operLog);
}
/**
* 查询系统操作日志集合
*
* @param operLog 操作日志对象
* @return 操作日志集合
*/
@Override
@DS("sharding")
public List<SysOperLog> selectOperLogList(SysOperLog operLog)
{
return operLogMapper.selectOperLogList(operLog);
}
/**
* 批量删除系统操作日志
*
* @param operIds 需要删除的操作日志ID
* @return 结果
*/
@Override
@DS("sharding")
public int deleteOperLogByIds(Long[] operIds)
{
return operLogMapper.deleteOperLogByIds(operIds);
}
/**
* 查询操作日志详细
*
* @param operId 操作ID
* @return 操作日志对象
*/
@Override
@DS("sharding")
public SysOperLog selectOperLogById(Long operId)
{
return operLogMapper.selectOperLogById(operId);
}
/**
* 清空操作日志
*/
@Override
@DS("sharding")
public void cleanOperLog()
{
operLogMapper.cleanOperLog();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
8、新增分库分表测试类TestOperlogController.java
package com.ruoyi.system.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.ruoyi.common.core.web.controller.BaseController;
import com.ruoyi.common.core.web.domain.AjaxResult;
import com.ruoyi.system.api.domain.SysOperLog;
import com.ruoyi.system.service.ISysOperLogService;
@RestController
@RequestMapping("/test/operlog")
public class TestOperlogController extends BaseController
{
@Autowired
private ISysOperLogService operLogService;
@GetMapping("/{method}")
public AjaxResult operlog(@PathVariable("method") String method)
{
SysOperLog operLog = new SysOperLog();
operLog.setTitle("测试数据");
operLog.setOperName("admin");
operLog.setRequestMethod(method);
return toAjax(operLogService.insertOperlog(operLog));
}
@GetMapping("/list")
public AjaxResult list()
{
return AjaxResult.success(operLogService.selectOperLogList(new SysOperLog()));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
9、启动RuoYiSystemApplication.java进行测试验证
订单数据库测试
访问 http://localhost:9201/order/add/1 (opens new window) 入到ry-order库sys_order表
查询 http://localhost:9201/order/list (opens new window)
查询 http://localhost:9201/order/query/1 (opens new window)
分库分表测试
访问 http://localhost:9201/test/operlog/GET (opens new window) 入到ry-log库sys_oper_log_get表
访问 http://localhost:9201/test/operlog/POST (opens new window) 入到ry-log库sys_oper_log_post表
访问 http://localhost:9201/test/operlog/PUT (opens new window) 入到ry-log库sys_oper_log_put表
访问 http://localhost:9201/test/operlog/DELETE (opens new window) 入到ry-log库sys_oper_log_delete表
查询 http://localhost:9201/test/operlog/list (opens new window)